A geração de música simbólica depende cada vez mais de modelos que prevêem sequências de notas musicais e suas características, mas as abordagens atuais geralmente tratam essas características como ordenadas rigidamente, limitando seu potencial. Hongju Su, Ke Li e Lan Yang, juntamente com Honggang Zhang e Yi-Zhe Song, desafiam essa suposição ao introduzir Amadeus, uma nova estrutura que vê os atributos musicais como um conjunto mais flexível e concorrente. O trabalho deles demonstra que a modelagem atribui bidirecionalmente, e não sequencialmente, melhora significativamente a qualidade e a velocidade da geração da música, superando os modelos de ponta existentes em vários benchmarks. Crucialmente, a equipe também apresenta um conjunto de dados de código aberto substancial, o conjunto de dados da Amadeus MIDI, para facilitar mais pesquisas e desenvolvimento nesse campo em rápida evolução e mostra a possibilidade de controle detalhado e guiado pelo usuário sobre música gerada.
Os modelos de geração de música simbólica normalmente modelam a música como uma sequência de atributos, assumindo uma estrutura de dependência fixa entre eles. No entanto, as observações sugerem que os atributos musicais são essencialmente simultâneos e não ordenados, em vez de estritamente seqüencial.
Modelos de idiomas grandes geram música simbólica
Avanços recentes na alavancagem de geração de música simbólica grande linguagem Modelos, originalmente projetados para texto, para criar peças musicais. Esses modelos visam gerar músicas estruturalmente sólidas, musicalmente expressivas e controláveis, permitindo especificação de gênero, humor ou estilo. Vários modelos surgiram, construindo técnicas anteriores. O Music Transformer foi um modelo inicial que aplica a arquitetura de transformadores à geração de música. O Musecoco gera música simbólica a partir de legendas de texto, enquanto o transformador da música pop se concentra nas expressivas composições de piano pop.
Outros modelos, como o transformador de palavras compostos e o transformador de jazz, exploram diferentes abordagens para modelar músicas completas e avaliar a música composta por IA. Desenvolvimentos recentes incluem difuso e disperso, megabyte, byte latente Transformer, Audio estável e mupt, cada um contribuindo com técnicas exclusivas para o campo. Modelos como Notagen, Melodyt5, Text2midi-Inferalign e XMusic avançam ainda mais a ponta, visando uma estrutura de geração de música simbólica generalizada e controlável. A pesquisa atual se concentra em melhorar a musicalidade e a expressividade, melhorar a controlabilidade, a escala para sequências mais longas e abordar a falta de dados de alta qualidade. O desenvolvimento de melhores métricas para avaliar a música composta por IA continua sendo um desafio significativo, impulsionando a necessidade de inovação contínua nesse campo.
Amadeus gera música com qualidade e velocidade aprimoradas
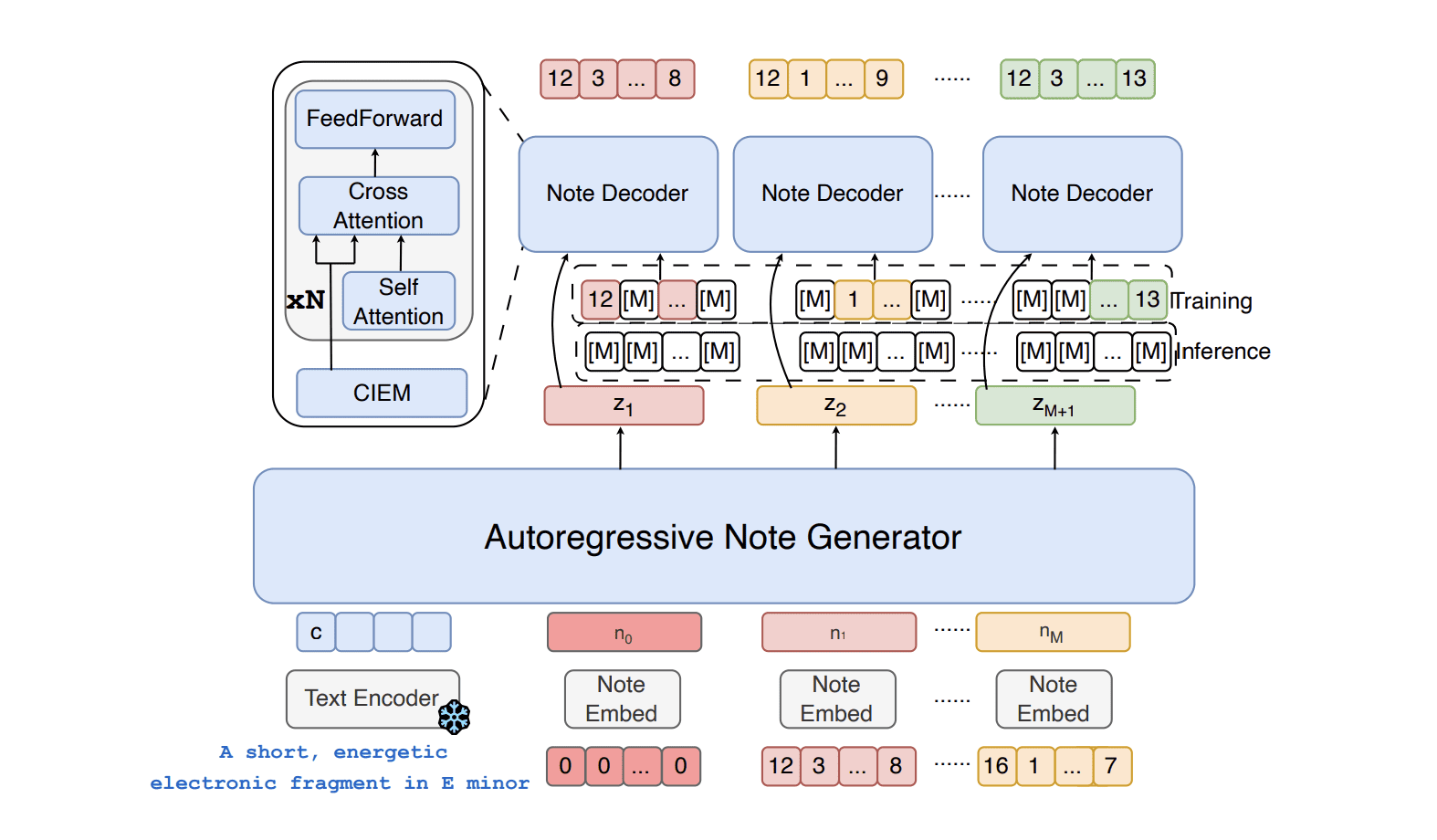
Os pesquisadores desenvolveram o Amadeus, uma nova estrutura para geração de música simbólica que supera significativamente os modelos existentes em qualidade e velocidade. Desafiando a abordagem seqüencial convencional, a equipe observou que os atributos de nota musical são simultâneos e não ordenados. Isso levou a uma arquitetura de dois níveis que combinava um modelo autoregressivo para sequências de notas com um modelo de difusão discreta bidirecional para atributos, alterando fundamentalmente a geração simbólica da música. Amadeus incorpora duas inovações principais: a estratégia de aprimoramento de discriminabilidade ao espaço latente da música e o módulo de aprimoramento de informações condicionais.
O primeiro utiliza um aprendizado contrastante aprimorado para amplificar a discriminabilidade das representações da música intermediária, enquanto o último emprega mecanismos de atenção para fortalecer a representação vetorial latente da nota, levando a uma decodificação mais precisa das anotações. As experiências demonstram que Amadeus alcança pelo menos um aumento de quatro vezes na velocidade em comparação com os métodos anteriores. Os resultados mostram que o Amadeus se destaca na qualidade da música, adesão à condição, controlabilidade de atributos e velocidade de inferência, permitindo trade-offs flexíveis entre esses fatores. 9 milhões de amostras pré-treinamento e 320.000 amostras anotadas de ajuste fino. Esse conjunto de dados e a inovadora estrutura da Amadeus prometem desbloquear novas possibilidades na composição auxiliada por computador e na geração de música.
A difusão simultânea supera a geração de música seqüencial
Amadeus apresenta uma nova abordagem da geração de música simbólica, desafiando a dependência da modelagem seqüencial de atributos musicais. A estrutura adota uma arquitetura de dois níveis, combinando um modelo autoregressivo para seqüências de notas com um modelo de difusão discreta bidirecional para atributos, tratando esses atributos como um conjunto simultâneo e não ordenado. As melhorias de desempenho são alcançadas por meio de estratégias de aprimoramento de discriminabilidade ao espaço latente da música e o módulo de aprimoramento de informações condicionais, que refinam a representação de dados musicais. As experiências demonstram que o Amadeus supera significativamente os modelos existentes em tarefas de geração de música incondicional e condicionada por texto, além de alcançar um aumento substancial na velocidade de geração. Os autores reconhecem que a otimização adicional é possível para equilibrar a eficiência computacional com a qualidade da geração, e trabalhos futuros explorarão as técnicas de aceleração sem perdas para permitir a geração de música em tempo real.
‘O artigo anterior pode incluir informações divulgadas por terceiros’
‘Alguns detalhes deste artigo foram extraídos da seguinte fonte Quantumzeitgeist.com’
‘ O artigo anterior foi obtido e traduzido do site internacional da celebrity.land ’ Source Link















{kind=link}