Esta postagem mostra como construir um sistema de pesquisa de vídeo multimodal escalonável que permite a pesquisa em linguagem natural em grandes conjuntos de dados de vídeo usando Amazônia Nova modelos e Serviço Amazon OpenSearch. Você aprenderá como ir além da marcação manual e das pesquisas baseadas em palavras-chave para permitir a pesquisa semântica que captura toda a riqueza do conteúdo de vídeo.
Demonstramos isso em grande escala processando 792.270 vídeos de dois Registro de dados abertos da AWS conjuntos de dados: Comuns Multimídia (787.479 vídeos, média de 37 segundos) e MEVA (4.791 vídeos, média de 5 minutos). O processamento de 8.480 horas de conteúdo de vídeo (30,5 milhões de segundos) levou 41 horas. Custo total do primeiro ano: US$ 27.328 (com OpenSearch sob demanda) ou US$ 23.632 (com instâncias reservadas do OpenSearch Service). O custo consistia em ingestão única (US$ 18.088) e Amazon OpenSearch Service anual (US$ 9.240 sob demanda ou US$ 5.544 reservados).
A repartição da ingestão é a seguinte:
- Computação Amazon Elastic Compute Cloud (Amazon EC2) (4 × c7i.48xlarge spot a US$ 2,57/hora × 41 horas): US$ 421
- Base Amazônica Embeddings Nova Multimodal (30,5 milhões de segundos × preço de lote de US$ 0,00056/segundo): US$ 17.096
- Marcação Nova Pro (792 mil vídeos × 600 tokens (média)): US$ 571
A solução gera embeddings audiovisuais usando AUDIO_VIDEO_COMBINED modo (ver Esquema da API Nova Multimodal Embeddings), armazena-os no OpenSearch Service e suporta pesquisa de texto para vídeo, vídeo para vídeo e pesquisa híbrida.
Visão geral da solução
A arquitetura consiste em dois fluxos de trabalho principais — ingestão e pesquisa — que trabalham juntos para permitir a pesquisa multimodal de vídeos em escala:
Pipeline de ingestão de vídeo:
O pipeline de ingestão usa quatro Amazon EC2 Instâncias c7i.48xlarge com 600 trabalhadores paralelos para processar 19.400 vídeos por hora. A API assíncrona tem um limite de simultaneidade de 30 trabalhos simultâneos por conta (consulte Cotas Amazon Bedrock), então o pipeline implementa uma fila de trabalhos com sondagem. Os trabalhadores enviam trabalhos até o limite de simultaneidade, pesquisam a conclusão e enviam novos trabalhos à medida que as vagas ficam disponíveis. Incorporações multimodais do Amazon Nova lida com o processamento de vídeo de forma assíncrona, segmentando vídeos em pedaços de 15 segundos (otimizado para capturar mudanças de cena enquanto mantém a contagem de incorporações gerenciável) e gerando incorporações de 1.024 dimensões. Essas incorporações foram escolhidas em 3072 dimensões para uma economia de custos de 3x do ponto de vista de armazenamento com impacto mínimo na precisão. O custo de geração de incorporação é independente das dimensões de incorporação. Amazon Nova Pro adiciona de 10 a 15 tags descritivas por vídeo a partir de uma taxonomia predefinida.
Observação: Amazon Nova 2 Lite oferece maior precisão com menor custo para tarefas de marcação. Recomendamos que você considere isso para novas implantações. O sistema armazena embeddings em um Índice OpenSearch k-NN para pesquisa semântica e tags de metadados em um índice de texto separado para correspondência de palavras-chave. Para pesquisa, você pode consultar vídeos de três maneiras: converter linguagem natural em embeddings para pesquisa de texto para vídeo, comparar embeddings de vídeo diretamente para pesquisa de vídeo para vídeo ou combinar ambas as abordagens em pesquisa híbrida.
Tipos de pesquisas habilitadas por esta solução:
- Pesquisa de texto para vídeo – Consultas de linguagem natural convertidas em embeddings para correspondência de similaridade semântica
- Pesquisa vídeo para vídeo – Encontre conteúdo semelhante comparando diretamente os embeddings de vídeo
- Pesquisa híbrida – Combina similaridade vetorial (peso de 70%) com correspondência de palavras-chave (peso de 30%) para máxima precisão
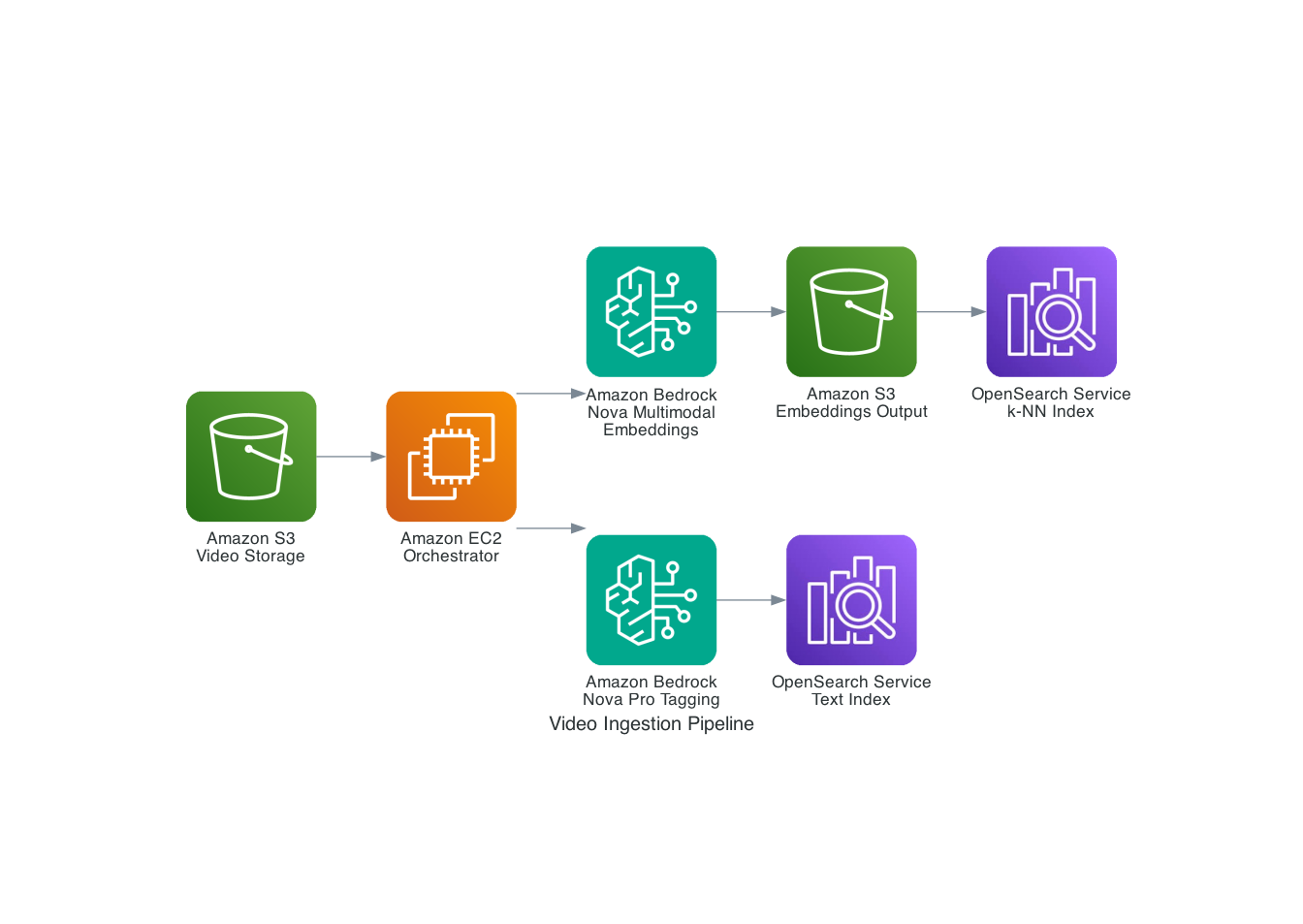
Pipeline de ingestão de vídeo
O diagrama a seguir ilustra o pipeline de ingestão e processamento de vídeo:
Figura 1: Pipeline de ingestão de vídeo mostrando o fluxo do armazenamento de vídeo S3 por meio de Nova Multimodal Embeddings e Nova Pro para índices OpenSearch duplos
O fluxo de trabalho de processamento de vídeo é o seguinte:
- Enviar vídeos para Serviço de armazenamento simples da Amazon (Amazon S3).
- Processe vídeos usando API assíncrona Nova Multimodal Embeddingsque segmenta vídeos automaticamente e gera embeddings. Um orquestrador pesquisa a conclusão do trabalho (a API assíncrona tem um limite de 30 trabalhos simultâneos por conta, consulte Cotas Amazon Bedrock) e recupera resultados do Amazon S3.
- Gere tags descritivas usando Nova Pro (ou Nova Lite para melhor precisão a um custo menor) a partir de uma taxonomia predefinida para recursos de pesquisa aprimorados.
- Incorporações de índice em Índice OpenSearch k-NN e tags no índice de texto.
Arquitetura de pesquisa de vídeo
O diagrama a seguir mostra a arquitetura de pesquisa completa:

Figura 2: Arquitetura de pesquisa de vídeo demonstrando três modos de pesquisa – texto para vídeo, vídeo para vídeo e pesquisa híbrida combinando k-NN e BM25
A arquitetura de pesquisa permite três modos:
- Texto para vídeo – Consultas em linguagem natural
- Vídeo para vídeo – Descoberta de conteúdo semelhante
- Híbrido – Correspondência combinada de semântica e palavras-chave
Pré-requisitos
Antes de começar, você precisará de:
- Um Conta AWS com acesso a Base Amazônica em
us-east-1(Os modelos Nova são habilitados por padrão com permissões IAM apropriadas) - Pitão 3.9 ou posterior instalado
- Interface de linha de comando da AWS (AWS CLI) configurado com credenciais apropriadas
- Um domínio do Amazon OpenSearch Service (r6g.large ou maior recomendado)
- Um Amazon S3 balde para armazenamento de vídeo e incorporação de saídas
- AWS Identity and Access Management (IAM) para Amazon Bedrock, OpenSearch Service e Amazon S3
A solução usa:
- Amazon Bedrock com Incorporações Multimodais Nova (amazon.nova-2-multimodal-embeddings-v1:0)
- Amazon Bedrock com Nova Pro (us.amazon.nova-pro-v1:0) ou Nova Lite (us.amazon.nova-2-lite-v1:0) para marcação
- Amazon OpenSearch Service 2.11 ou posterior com Plug-in k-NN
- Amazon S3 para armazenamento de vídeo e incorporação
Passo a passo
Etapa 1: criar funções e políticas do IAM
Crie um Função do IAM com permissões para invocar modelos do Amazon Bedrock, gravar em índices OpenSearch e ler/gravar objetos S3.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"bedrock:InvokeModel",
"bedrock:StartAsyncInvoke",
"bedrock:GetAsyncInvoke",
"bedrock:ListAsyncInvoke"
],
"Resource": [
"arn:aws:bedrock:us-east-1::foundation-model/amazon.nova-2-multimodal-embeddings-v1:0",
"arn:aws:bedrock:us-east-1::foundation-model/us.amazon.nova-pro-v1:0"
]
},
{
"Effect": "Allow",
"Action": [
"es:ESHttpPost",
"es:ESHttpPut",
"es:ESHttpGet"
],
"Resource": "arn:aws:es:us-east-1:ACCOUNT_ID:domain/DOMAIN_NAME/*"
},
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:PutObject"
],
"Resource": [
"arn:aws:s3:::amzn-s3-demo-video-bucket/*",
"arn:aws:s3:::amzn-s3-demo-embedding-bucket/*"
]
}
]
}
Etapa 2: configurar índices do OpenSearch Service
Crie dois Índices do serviço OpenSearch: um para incorporações de vetores (k-NN) e um para metadados de texto. Esta arquitetura suporta pesquisa semântica e consultas híbridas.
from opensearchpy import OpenSearch, RequestsHttpConnection
from requests_aws4auth import AWS4Auth
import boto3
session = boto3.Session()
credentials = session.get_credentials()
awsauth = AWS4Auth(
credentials.access_key,
credentials.secret_key,
session.region_name,
'es',
session_token=credentials.token
)
opensearch_client = OpenSearch(
hosts=[{'host': 'YOUR_OPENSEARCH_ENDPOINT', 'port': 443}],
http_auth=awsauth,
use_ssl=True,
verify_certs=True,
connection_class=RequestsHttpConnection
)
# Create k-Nearest Neighbors (k-NN) index for embeddings
knn_index_body = {
"settings": {
"index.knn": True,
"number_of_shards": 2,
"number_of_replicas": 1
},
"mappings": {
"properties": {
"video_id": {"type": "keyword"},
"segment_index": {"type": "integer"},
"timestamp": {"type": "float"},
"embedding": {
"type": "knn_vector",
"dimension": 1024,
"method": {
"name": "hnsw",
"space_type": "cosinesimilarity",
"engine": "faiss"
}
},
"s3_uri": {"type": "keyword"}
}
}
}
opensearch_client.indices.create(
index="video-embeddings-knn",
body=knn_index_body
)
# Create text index for metadata
text_index_body = {
"settings": {
"number_of_shards": 2,
"number_of_replicas": 1
},
"mappings": {
"properties": {
"video_id": {"type": "keyword"},
"segment_index": {"type": "integer"},
"tags": {"type": "text", "analyzer": "standard"}
}
}
}
opensearch_client.indices.create(
index="video-embeddings-text",
body=text_index_body
)Etapa 3: Processar vídeos com Nova Multimodal Embeddings
O API assíncrona Amazon Bedrock processa vídeos e gera incorporações. Ele segmenta os vídeos em pedaços de 15 segundos e combina informações de áudio e visuais.
import boto3
import json
import time
bedrock = boto3.client('bedrock-runtime', region_name="us-east-1")
def generate_video_embeddings(video_s3_uri, output_s3_uri):
"""Generate embeddings for a video using Nova MME async API."""
# Start async job
response = bedrock.start_async_invoke(
modelId="amazon.nova-2-multimodal-embeddings-v1:0",
modelInput={
"taskType": "SEGMENTED_EMBEDDING",
"segmentedEmbeddingParams": {
"embeddingPurpose": "GENERIC_INDEX",
"embeddingDimension": 1024,
"video": {
"format": "mp4",
"embeddingMode": "AUDIO_VIDEO_COMBINED",
"source": {"s3Location": {"uri": video_s3_uri}},
"segmentationConfig": {"durationSeconds": 15}
}
}
},
outputDataConfig={"s3OutputDataConfig": {"s3Uri": output_s3_uri}}
)
# Poll for completion
invocation_arn = response["invocationArn"]
while True:
job = bedrock.get_async_invoke(invocationArn=invocation_arn)
if job["status"] == "Completed":
return read_embeddings_from_s3(job["outputDataConfig"]["s3OutputDataConfig"]["s3Uri"])
elif job["status"] in ["Failed", "Expired"]:
raise RuntimeError(f"Job failed: {job.get('failureMessage')}")
time.sleep(10)
def manage_concurrent_jobs(bedrock_client, video_queue, max_concurrent=30):
"""Manage 30 concurrent async jobs within quota limits."""
active_jobs = {}
while video_queue or active_jobs:
# Submit new jobs up to limit (uses same start_async_invoke call as above)
while len(active_jobs) Etapa 4: gerar tags de metadados com Nova Pro ou Nova Lite
Gere tags descritivas para vídeos usando Nova Pro (ou Nova Lite para melhor precisão a um custo menor) para permitir pesquisa híbrida que combina correspondência semântica e de palavras-chave.
VALID_TAGS = [
"person", "vehicle", "animal", "building", "nature", "indoor", "outdoor",
"walking", "running", "sitting", "standing", "talking", "driving",
"day", "night", "sunny", "cloudy", "urban", "rural", "beach", "forest",
"sports", "music", "food", "technology", "crowd", "solo"
]
def generate_tags(video_s3_uri, sample_frame_count=3):
"""Generate descriptive tags using Nova Pro or Nova Lite."""
prompt = f"""Analyze this video and select 10-15 tags from this predefined list that best describe the content:
{', '.join(VALID_TAGS)}
Only return tags from this list as a comma-separated list. Do not invent new tags."""
response = bedrock.converse(
modelId="us.amazon.nova-pro-v1:0", # Or use us.amazon.nova-2-lite-v1:0
messages=[{
"role": "user",
"content": [{
"video": {
"format": "mp4",
"source": {"s3Location": {"uri": video_s3_uri}}
}
}, {
"text": prompt
}]
}]
)
# Parse tags from response and validate against taxonomy
tags_text = response['output']['message']['content'][0]['text']
tags = [tag.strip().lower() for tag in tags_text.split(',')]
# Filter to only valid tags from our taxonomy
valid_tags = [tag for tag in tags if tag in VALID_TAGS]
return valid_tags
Etapa 5: Indexar embeddings e tags no OpenSearch Service
Armazene os embeddings e tags gerados no OpenSearch Service usando indexação em massa para eficiência.
from opensearchpy import helpers
def index_video_data(video_id, s3_uri, embeddings, tags):
"""Index embeddings and tags in OpenSearch."""
# Prepare bulk actions for k-NN index
knn_actions = []
for idx, emb in enumerate(embeddings):
doc_id = f"{video_id}_{idx}"
knn_actions.append({
"_index": "video-embeddings-knn",
"_id": doc_id,
"_source": {
"video_id": video_id,
"segment_index": idx,
"timestamp": emb['start_time'],
"embedding": emb['embedding'],
"s3_uri": s3_uri
}
})
# Bulk index embeddings
helpers.bulk(opensearch_client, knn_actions)
# Prepare bulk actions for text index
text_actions = []
for idx in range(len(embeddings)):
doc_id = f"{video_id}_{idx}"
text_actions.append({
"_index": "video-embeddings-text",
"_id": doc_id,
"_source": {
"video_id": video_id,
"segment_index": idx,
"tags": " ".join(tags)
}
})
# Bulk index tags
helpers.bulk(opensearch_client, text_actions)
print(f"Indexed {len(embeddings)} segments for video {video_id}")
Etapa 6: implementar a funcionalidade de pesquisa
Após a conclusão da ingestão, pesquise os vídeos indexados de três maneiras. A implementação visa consultas de baixa latência.
Inicialize o cliente do OpenSearch Service para pesquisa
Primeiro, crie o cliente OpenSearch Service para operações de pesquisa:
from opensearchpy import OpenSearch, RequestsHttpConnection
from requests_aws4auth import AWS4Auth
import boto3
def create_opensearch_client():
"""Create OpenSearch client with AWS authentication."""
session = boto3.Session(region_name="us-east-1")
credentials = session.get_credentials()
awsauth = AWS4Auth(
credentials.access_key,
credentials.secret_key,
'us-east-1',
'es',
session_token=credentials.token
)
return OpenSearch(
hosts=[{'host': 'YOUR_OPENSEARCH_ENDPOINT', 'port': 443}],
http_auth=awsauth,
use_ssl=True,
verify_certs=True,
connection_class=RequestsHttpConnection,
timeout=30
)
# Create client
opensearch_client = create_opensearch_client()
Pesquisa semântica de texto para vídeo
Converta consultas de linguagem natural em incorporações usando a API de sincronização e, em seguida, execute uma pesquisa de similaridade k-NN:
def search_text_to_video(query_text, opensearch_client, k=10):
"""Search videos using natural language query converted to embedding."""
bedrock_client = boto3.client('bedrock-runtime', region_name="us-east-1")
# Use SINGLE_EMBEDDING task type for text-to-embedding conversion
# VIDEO_RETRIEVAL purpose optimizes embeddings for searching video content
request_body = {
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "VIDEO_RETRIEVAL",
"embeddingDimension": 1024,
"text": {
"truncationMode": "END",
"value": query_text
}
}
}
response = bedrock_client.invoke_model(
modelId='amazon.nova-2-multimodal-embeddings-v1:0',
body=json.dumps(request_body),
accept="application/json",
contentType="application/json"
)
response_body = json.loads(response['body'].read())
# Response structure: {"embeddings": [{"embeddingType": "TEXT", "embedding": [...]}]}
query_embedding = response_body['embeddings'][0]['embedding']
# Perform k-NN search against video embeddings
search_body = {
"query": {
"knn": {
"embedding": {
"vector": query_embedding,
"k": k
}
}
},
"size": k,
"_source": ["video_id", "segment_index", "timestamp", "s3_uri"]
}
response = opensearch_client.search(
index="video-embeddings-knn",
body=search_body
)
# Extract results
return [{'score': hit['_score'],
'video_id': hit['_source']['video_id'],
'segment_index': hit['_source']['segment_index'],
'timestamp': hit['_source'].get('timestamp', 0)}
for hit in response['hits']['hits']]
Pesquisa de texto com BM25 (correspondência de palavras-chave)
Use a pontuação OpenSearch BM25 para correspondência de palavras-chave em tags sem gerar embeddings:
def search_text_bm25(search_term, opensearch_client, k=10):
"""Search videos using BM25 keyword matching on tags field."""
# Search text index using match query on tags
search_body = {
"query": {
"match": {
"tags": search_term
}
},
"size": k,
"_source": ["video_id", "segment_index", "tags"]
}
response = opensearch_client.search(
index="video-embeddings-text",
body=search_body
)
return response['hits']['hits'] # Extract results (same pattern as above)
Pesquisa vídeo a vídeo
Recupere a incorporação de um vídeo existente do OpenSearch Service e pesquise conteúdo semelhante – não é necessária nenhuma chamada de API do Amazon Bedrock:
def search_video_to_video(query_video_id, query_segment_index, opensearch_client, k=10):
"""Find similar videos using a reference video segment."""
# Get the embedding from the reference video segment
sample_query = {
"query": {
"bool": {
"must": [
{"term": {"video_id": query_video_id}},
{"term": {"segment_index": query_segment_index}}
]
}
},
"_source": ["video_id", "segment_index", "embedding"]
}
sample_response = opensearch_client.search(
index="video-embeddings-knn",
body=sample_query
)
if not sample_response['hits']['hits']:
return []
sample_doc = sample_response['hits']['hits'][0]['_source']
query_embedding = sample_doc.get('embedding')
# Perform k-NN search with the embedding
search_body = {
"query": {
"knn": {
"embedding": {
"vector": query_embedding,
"k": k
}
}
},
"size": k,
"_source": ["video_id", "segment_index", "timestamp"]
}
response = opensearch_client.search(
index="video-embeddings-knn",
body=search_body
)
return response['hits']['hits'] # Extract results as needed
Pesquisa híbrida
Combine a correspondência semântica de palavras-chave k-NN e BM25 recuperando resultados de ambos os índices e mesclando com pontuação ponderada:
def search_hybrid(query_text, opensearch_client, k=10, vector_weight=0.7, text_weight=0.3):
"""Hybrid search combining k-NN semantic search and BM25 text matching."""
# Generate query embedding (use same code as search_text_to_video above)
query_embedding = generate_query_embedding(query_text) # See text-to-video example
# Get k-NN results (same query as search_text_to_video)
knn_response = opensearch_client.search(
index="video-embeddings-knn",
body={"query": {"knn": {"embedding": {"vector": query_embedding, "k": 20}}}, "size": 20}
)
# Get BM25 text results (same query as search_text_bm25)
text_response = opensearch_client.search(
index="video-embeddings-text",
body={"query": {"match": {"tags": query_text}}, "size": 20}
)
# Combine results with weighted scoring
knn_hits = knn_response['hits']['hits']
text_hits = text_response['hits']['hits']
combined = {}
for hit in knn_hits:
vid = hit['_source']['video_id']
seg = hit['_source']['segment_index']
key = f"{vid}_{seg}"
combined[key] = {
'video_id': vid,
'segment_index': seg,
'tags': hit['_source'].get('tags', ''),
'vector_score': hit['_score'],
'text_score': 0,
'combined_score': hit['_score'] * vector_weight
}
for hit in text_hits:
vid = hit['_source']['video_id']
seg = hit['_source']['segment_index']
key = f"{vid}_{seg}"
if key in combined:
combined[key]['text_score'] = hit['_score']
combined[key]['combined_score'] += hit['_score'] * text_weight
else:
combined[key] = {
'video_id': vid,
'segment_index': seg,
'tags': hit['_source'].get('tags', ''),
'vector_score': 0,
'text_score': hit['_score'],
'combined_score': hit['_score'] * text_weight
}
# Sort by combined score and return top k
sorted_results = sorted(combined.values(), key=lambda x: x['combined_score'], reverse=True)[:k]
return sorted_results
# Usage example - search with natural language query
query = "person walking on beach at sunset"
hybrid_results = search_hybrid(query, opensearch_client, k=10)
for r in hybrid_results:
print(f"Combined: {r['combined_score']:.4f} (Vector: {r['vector_score']:.4f}, Text: {r['text_score']:.4f})")
print(f" Video: {r['video_id']}, Segment: {r['segment_index']}")
print(f" Tags: {r['tags']}\n")
Desempenho de pesquisa em escala
Depois de indexar todos os 792.218 vídeos, medimos o desempenho da pesquisa em todos os três métodos.
As latências de consulta medidas em 792.218 vídeos são as seguintes:
- Pesquisa semântica k-NN: ~76ms (usando HNSW escala logarítmica)
- BM25 pesquisa de texto: ~30ms
- Pesquisa híbrida: ~106ms
Após indexar e armazenar todos os 792.218 vídeos e gerar embeddings, os requisitos de armazenamento são os seguintes:
- Índice k-NN: 28,8 GB para vídeos de 792K
- Índice de texto: 1,0 GB para vídeos de 792K
- Total: 29,8 GB (gerenciável em clusters OpenSearch modernos)
O algoritmo Hierarchical Navigable Small World (HNSW) usado para pesquisa k-NN fornece complexidade de tempo logarítmica, o que significa que os tempos de pesquisa crescem lentamente à medida que o conjunto de dados aumenta. Todos os três métodos de pesquisa mantêm tempos de resposta inferiores a 200 ms, mesmo em escala de vídeo de 792K, atendendo aos requisitos de produção para aplicações de pesquisa interativas.
Coisas para saber
Considerações de desempenho e custo
O tempo de processamento do vídeo depende da duração do vídeo. Em nossos testes, um vídeo de 45 segundos levou aproximadamente 70 segundos para ser processado usando a API assíncrona. O processamento inclui segmentação automática, geração de incorporação para cada segmento e saída para o Amazon S3. As operações de pesquisa são escalonadas com eficiência: nossos testes mostram que, mesmo em vídeos de 792 mil, a pesquisa semântica é concluída em menos de 80 ms, a pesquisa de texto em menos de 30 ms e a pesquisa híbrida em menos de 11 0 ms. Use incorporações de 1.024 dimensões em vez de 3.072 para reduzir os custos de armazenamento e, ao mesmo tempo, manter a precisão. A Nova Multimodal Embeddings cobra por segundo de entrada de vídeo (US$ 0,00056/lote de segundo), portanto, a duração do vídeo — e não a dimensão de incorporação ou segmentação — determina o custo de processamento. A API assíncrona é mais econômica do que processar quadros individualmente. Para o OpenSearch Service, o uso de instâncias r6g oferece melhor relação custo-desempenho do que os tipos de instância anteriores, e você pode implementar camadas para mover dados frios para o Amazon S3 para obter economias adicionais.
Escalando para produção
Para implantações de produção com grandes videotecas, considere usar Lote AWS para processar vídeos em paralelo em várias instâncias de computação. Você pode particionar seu conjunto de dados de vídeo e atribuir subconjuntos a diferentes trabalhadores. Monitor Integridade do cluster do OpenSearch Service e dimensione nós de dados à medida que seu índice cresce. A arquitetura de dois índices é bem dimensionada porque as pesquisas k-NN e de texto podem ser otimizadas de forma independente.
Ajuste de precisão de pesquisa
Ajuste os pesos da pesquisa híbrida com base no seu caso de uso. A divisão padrão 0,7/0,3 (vetor/texto) favorece a similaridade semântica para a maioria dos cenários. Se você tiver tags de metadados de alta qualidade, aumentar a espessura do texto para 0,5 pode melhorar os resultados. Recomendamos que você teste diferentes configurações com seu conteúdo específico para encontrar um equilíbrio.
Limpar
Para evitar cobranças contínuas, exclua os recursos que você criou:
- Exclua o Domínio do serviço OpenSearch no console do Amazon OpenSearch Service
- Esvazie e exclua o Baldes S3 usado para vídeos e incorporações
- Exclua qualquer Funções do IAM criado especificamente para esta solução
Observe que as cobranças do Amazon Bedrock são baseadas no uso, portanto, nenhuma limpeza é necessária para os próprios modelos do Amazon Bedrock.
Conclusão
Este passo a passo abordou a construção de um sistema de pesquisa de vídeo multimodal para consultas em linguagem natural em conteúdo de vídeo. A solução usa modelos Amazon Bedrock Nova para gerar embeddings. Esses embeddings capturam informações de áudio e visuais, armazenam-nas de forma eficiente no OpenSearch Service usando uma arquitetura de dois índices e fornecem três modos de pesquisa para diferentes casos de uso. A abordagem de processamento assíncrono é dimensionada para lidar com grandes bibliotecas de vídeo, e o recurso de pesquisa híbrida combina correspondência semântica e baseada em palavras-chave para máxima precisão. Você pode ampliar essa base adicionando recursos como pesquisa de similaridade entre vídeos, implementando armazenamento em cache para consultas pesquisadas com frequência ou integrando-se ao AWS Batch para processamento paralelo de grandes conjuntos de dados.
Para saber mais sobre as tecnologias utilizadas nesta solução, consulte Incorporações multimodais do Amazon Nova e Pesquisa híbrida com Amazon OpenSearch Service.
Sobre os autores
‘O artigo anterior pode incluir informações divulgadas por terceiros’
‘Alguns detalhes deste artigo foram extraídos da seguinte fonte aws.amazon.com’
‘ O artigo anterior foi obtido e traduzido do site internacional da celebrity.land ’ Source Link















{kind=link}