CINGAPURAAssim, 15 de agosto de 2025 / PRNEWSWIRE/ – A semana de lançamento da Ai Technology AI Skywork começou oficialmente 11 de agosto. De 11 de agosto a 15 de agostoum novo modelo foi lançado todos os dias por cinco dias consecutivos, cobrindo modelos de ponta para cenários de IA multimodais.
A partir de agora, a Skywork já lançou os modelos Skyreels-A3, Matrix-Game 2.0, Matrix-3D, Skywork Unipic 2.0 e Skywork Deep Research Agent. Sobre 15 de agostoo modelo Mureka V7.5 foi lançado oficialmente, marcando a conclusão bem -sucedida da semana de lançamento da Skywork AI Technology.
Mureka V7.5 alcançou novos patamares em sua interpretação das músicas chinesas. O modelo Demonstra melhorias significativas não apenas no timbre vocal e nas técnicas instrumentais, mas também na articulação lírica e expressão emocional.
Primeiro, construindo sua compreensão robusta dos estilos e elementos musicais chineses, o modelo de compreensão de Mureka oferece insights profundos – abrangendo canções folclóricas tradicionais, peças operatórias, hits clássicos de mandopop e música folclórica contemporânea. Esse profundo domínio da diversidade musical e nuances culturais permite que o modelo capture e expresse com precisão a essência artística única e as sutilezas emocionais na interpretação e na geração da música chinesa.
Segundo, para obter vocais gerados pela IA mais autênticos e emocionalmente expressivos, aumentamos significativamente nossa tecnologia ASR, adaptando-a a características musicais e estabelecendo-a como um complemento poderoso ao nosso módulo de compreensão. Essa tecnologia analisa as performances vocais em nível granular, indo além do reconhecimento básico da lírica para examinar as técnicas de desempenho, incluindo controle de respiração, dinâmica emocional e nuances de articulação. Analisando inteligentemente frases musicais, detectando pontos de respiração natural e identificando pausas estruturais – mantendo o reconhecimento preciso da seção – oferece vocais sintetizados com coerência estrutural sem precedentes e realismo perceptivo.
Os dados vocais de alta resolução capturados são devolvidos ao modelo generativo, aumentando significativamente a naturalidade dos vocais sintetizados, o realismo da respiração e a expressividade emocional enquanto reduz os artefatos mecânicos. Isso permite que as músicas geradas pela IA atinjam a fluidez humana-principalmente ao reproduzir o fraseado rítmico distinto e o controle da respiração exclusivos da música vocal chinesa.
Essa combinação única de experiência culturalmente informada e as idéias granulares da ASR Technology, otimizadas pela Song, constitui nossa vantagem competitiva definitiva na geração de música chinesa.
Mureka V7.5 não apenas “entende” os requisitos de produção melódica e rítmica, mas também interpreta profundamente e replica as emoções sufadas e expressões artísticas inerentes a diferentes contextos culturais – especialmente a música chinesa. Essa capacidade fornece uma base técnica robusta para gerar músicas que são culturalmente autênticas e esteticamente atraentes, equilibrando a profundidade artística com o realismo realista.
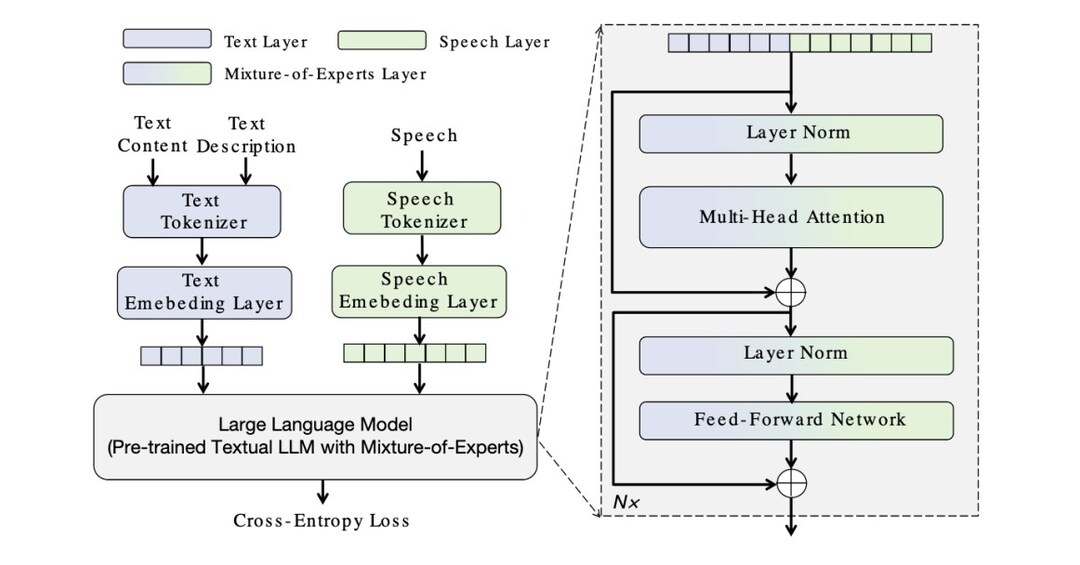
Para modelos de voz, a equipe de voz da Skywork lançou MOE-TTS-A primeira estrutura de texto em discurso de caracteres baseada em especialização.
Como uma nova estrutura TTS especializada em descrições fora do domínio, essa tecnologia permite um controle preciso sobre as características vocais por meio de entradas de linguagem natural (por exemplo, “uma voz juvenil cristalina com batata frita magnética”). Apesar de usar apenas dados de treinamento de fonte aberta, ele atinge a consistência da voz do personagem a par ou superior aos sistemas comerciais proprietários.
Nos últimos anos, o TTS descritivo demonstrou potencial significativo entre assistentes virtuais, criação de conteúdo de áudio e seres humanos digitais. No entanto, a pesquisa acadêmica tem sido limitada por Disetros escassos de descrição e baixa generalização do modelo para semântica de domínio aberto. Essas limitações freqüentemente levam a saídas vocais incompatíveis – principalmente ao interpretar a linguagem figurativa, como metáforas ou analogias.
A introdução do MOE-TTS apresenta uma solução promissora para esse desafio principal. A estrutura integra de forma inovadora Modelo de Linguagem Grande Textual pré-treinado (LLM) com especializado Módulos de especialistas em falaempregando especialistas dedicados para cada modalidade. Sua arquitetura de transformadores incorpora um novo roteamento de modalidade que permite a otimização independente das vias de texto e voz sem interferência. Enquanto mantém congelados os parâmetros de texto, a estrutura atinge o alinhamento cruzado eficiente, fornecendo assim recursos de generalização com “Degradação do conhecimento zero. ”
Em avaliações abrangentes que abrangem os conjuntos de testes de descrição no domínio e fora do domínio, o MOE-TTS foi comparado com os principais modelos proprietários de TTS em seis dimensões. Os resultados revelam as vantagens estatisticamente significativas da MOE-TTS nas métricas de controle acústico-particularmente o alinhamento da expressividade estilística (SEA) e o alinhamento geral (OA)-com esses ganhos de precisão explicando diretamente seu desempenho superior na correspondência lingüística complexa da descrição.
A liberação do MOE-TTS fornece à academia a primeira solução reproduzível de TTS fora do domínio, ao demonstrar conclusivamente a eficácia de Arquiteturas em declínio da modalidade com transferência de conhecimento congelado na síntese da fala. Esse inovador marca um passo crítico para fazer a transição do setor de sistemas de “controle de etiquetas fechados” para “controle de forma livre de linguagem natural”-uma mudança de paradigma que redefinirá as experiências do usuário em seres humanos digitais, assistentes virtuais e plataformas imersivas de criação de conteúdo.
Moe-tts está atualmente sob iteração ativa, com planos de integrá-la ao Mureka-declara Plataforma como um modelo fundamental para a síntese de voz de caracteres. Isso fornecerá aos desenvolvedores e criadores globais com recursos de síntese de fala aberta, eficiente e personalizável.
Experimente o novo modelo V7.5
Desbloqueie infinitas possibilidades na criação musical!
Experimente agora: www.mureka.ai
Fonte Skywork Ai Pte Ltd
‘O artigo anterior pode incluir informações divulgadas por terceiros’
‘Alguns detalhes deste artigo foram extraídos da seguinte fonte www.prnewswire.com’
‘ O artigo anterior foi obtido e traduzido do site internacional da celebrity.land ’ Source Link















{kind=link}